10 octobre 2023
Intégrez vos données métiers au modèle OpenAI GPT avec Next.js

7 minutes de lecture

Ces deux dernières années ont vu des avancées significatives dans le domaine du traitement du langage naturel. L'une des avancées les plus remarquables est l'émergence des Language Model-based Learning (LLMs), tels que le modèle GPT, suivi par BARD et Llama. Ces modèles sont aujourd'hui facilement utilisables directement via des API. Dans le domaine du développement, l'utilisation d'API ouvre généralement la voie à une démocratisation de la technologie, facilitant ainsi son adoption à grande échelle au sein des écosystèmes applicatifs. Cela se traduit par l'apparition de nombreuses librairies / SDK permettant de manipuler plus simplement ces modèles (Langchain, Vercel AI SDK…).
Next.js tiens désormais une place centrale au sein de notre stack technique, c'est pourquoi nous vous proposons aujourd'hui d'évoquer l'intégration du modèle GPT d'OpenAI dans une application Next.js grâce au Vercel AI SDK. Nous verrons également comment intégrer nos données dans l'usage de ce modèle.
Au programme
L'une des limites des modèles comme GPT est de ne pas avoir accès à des données temps réelles. En effet, ces modèles sont entraînés et leurs connaissances s'arrêtent à un instant T. OpenAI a récemment ajouté une fonctionnalité très intéressante à son API : la possibilité d'appeler des fonctions.
L'idée est donc d'utiliser le modèle GPT comme brique de raisonnement et de définir des fonctions permettant d'intégrer nos données métiers dans le raisonnement du modèle.
Nous allons donc développer un agent conversationnel permettant de répondre à des questions quant au status d'une commande sur un site e-commerce.
Initialisation du projet
Pour commencer, voici la stack technique de notre projet :
- ▲ Framework Next.js (13, app routeur) pour la partie front et API ;
- 🤖 Vercel AI SDK pour l'intégration du modèle GPT ;
- 🧠 OpenAI API pour l'accès au modèle GPT ;
- ⚙️ Prisma pour l'accès à la base de données.
Création du projet Next.js
Commençons par créer un projet Next.js (laissez les options par défaut) :
npx create-next-app@latest
Ajouter le SDK Vercel AI ainsi que le SDK d'OpenAI :
yarn add ai openai
SDK Vercel AI
Le SDK Vercel AI fournit un ensemble de fonctions permettant d'abstraire et faciliter les appels aux différences services d'AI tels que OpenAI ou encore HuggingFace pour ne citer que les plus connus.
Dans notre exemple, nous allons donc utiliser l'API d'OpenAI. Afin de pouvoir l'utiliser, il vous faudra créer une clé d'API.
Ceci fait, commençons par ajouter une route à notre API afin d'interroger le modèle GPT :
// app/api/chat/route.ts
import OpenAI from 'openai'
import { OpenAIStream, StreamingTextResponse } from 'ai'
// Création du client d'API OpenAI
const openai = new OpenAI({
apiKey: process.env.OPENAI_API_KEY!,
})
// Création d'une route POST avec Next.js
export async function POST(req: Request) {
// Récupération de l'attribut messages depuis la payload POST
const { messages } = await req.json()
// Appel au modèle GPT
const response = await openai.chat.completions.create({
model: 'gpt-3.5-turbo',
stream: true,
messages,
})
// Conversion de la réponse d'OpenAI en un stream grâce au helper OpenAIStream
const stream = OpenAIStream(response)
// Retourne la réponse au client sous forme de steam
return new StreamingTextResponse(stream)
}
Notre route d’API est prête à être appelée depuis notre front. Attention cependant à de tels endpoints, en l'état n'importe quel utilisateur peut l'utiliser et donc consommer votre quota d'appel à l'API d'OpenAI. Il convient donc de mettre des garde fous comme un token CSRF.
Ajoutons notre chat côté client :
'use client'
import { useChat } from 'ai/react'
export default function Chat() {
const { messages, input, handleInputChange, handleSubmit } = useChat({
api: '/api/chat',
})
return (
<div className="m-2 p-2 max-w-lg">
{messages.map((m) => (
<div className="mb-1" key={m.id}>
{m.role === 'user' ? 'Moi: ' : 'HAL 9000: '}
{m.content}
</div>
))}
<form onSubmit={handleSubmit}>
<input
className="rounded-md p-1 text-gray-900 shadow-sm ring-1 ring-inset ring-gray-300 mr-2 mt-4"
value={input}
onChange={handleInputChange}
/>
<button type="submit">Envoyer</button>
</form>
</div>
)
}
Nous pouvons voir que l’utilisation du hook useChat permet d’abstraire une grande partie de la complexité du code. Le hook va envoyer automatiquement votre message à votre endpoint d’API (par défaut /api/chat), récupérer la réponse streamée et mettre à jour le state.
En l’état, nous avons développé une simple interface de discussion avec le modèle GPT, sympathique mais pas très utile :
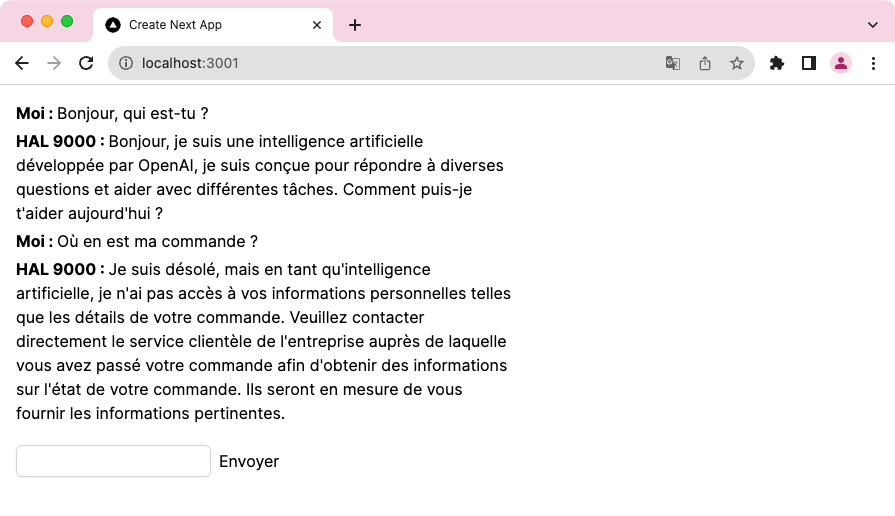
Nous allons voir maintenant comment introduire de la donnée métier au sein de cet agent conversationnel afin qu'il sache répondre à la question : "Où en est ma commande ?".
Intégration de données métiers
Partons du principe que nous souhaitons ajouter une assistance sur notre site e-commerce permettant la suivie des commandes. Pour cela, le modèle GPT doit avoir connaissance de nos différentes commandes.
Base de données avec Prisma
Nous allons passer par Prisma pour gérer notre base de données (pour cet exemple une simple base de données SQLite suffit) :
yarn add prisma
npx prisma init
Commençons par modifier le schéma Prisma afin de définir nos deux tables Order et Item :
generator client {
provider = "prisma-client-js"
}
datasource db {
provider = "sqlite"
url = "file:./dev.db"
}
model Order {
id Int @id @default(autoincrement())
reference String
createdAt DateTime @default(now())
updatedAt DateTime? @updatedAt
status String
items Item[]
@@map("orders")
}
model Item {
id Int @id @default(autoincrement())
name String
quantity Int
price Int
orderId Int
order Order @relation(fields: [orderId], references: [id])
@@map("items")
}
Nous pouvons désormais synchroniser/créer notre base de données :
npx prisma dev migrate
Voici nos données pour cet exemple :
INSERT INTO "orders" ("id", "reference", "createdAt", "updatedAt", "status") VALUES
('1', 'A3D2023', '2023-07-18 13:32:11', '2023-07-18 13:32:11', 'shipped');
INSERT INTO "items" ("id", "name", "quantity", "price", "orderId") VALUES
('1', 'A4 Print risographie', '2', '2300', '1'),
('2', 'A3 Print', '1', '1300', '1');
Fonctions personnalisées OpenAI
Depuis la version 3.5 turbo de GPT, il est désormais possible de définir des fonctions personnalisées au sein du workflow. Nous allons définir une fonction permettant de récupérer les informations d’une commande à partir d’un id :
import type { ChatCompletionCreateParams } from 'openai/resources/chat'
const functions: ChatCompletionCreateParams.Function[] = [
{
name: 'get_order_status',
description: 'Get the status of an order',
parameters: {
type: 'object',
properties: {
orderReference: {
type: 'string',
description: 'The reference of the order',
},
},
required: ['orderReference'],
},
},
]
Nous pouvons ensuite passer cette variable à notre fonction createChatCompletion :
const response = await openai.chat.completions.create({
model: 'gpt-3.5-turbo',
stream: true,
messages,
functions,
})
En décrivant simplement cette fonction, le modèle GPT déduit automatiquement, en fonction de la demande de l'utilisateur, s'il doit l'appeler ou non. Il nous reste plus qu'à définir le comportement de cette fonction au cas où le modèle décide de l'appeler :
const stream = OpenAIStream(response, {
experimental_onFunctionCall: async ({ name, arguments: args }, createFunctionCallMessages) => {
if (name === 'get_order_status') {
const ref = args.orderReference as string
const order = await db.order.findFirst({
where: { reference: ref },
select: { status: true, items: true },
})
const newMessages = createFunctionCallMessages(
order
? {
orderStatus: order.status,
items: order.items.map((item) => ({
name: item.name,
quantity: item.quantity,
})),
}
: { orderStatus: 'not_found' }
)
return openai.chat.completions.create({
messages: [...messages, ...newMessages],
stream: true,
model: MODEL_NAME,
functions,
})
}
return messages
},
})
Encore une fois, le modèle GPT va, à partir du json retourné, générer une réponse naturelle à l’utilisateur afin de lui donner des informations quant à sa commande. Voici cette fois-ci le dialogue généré :
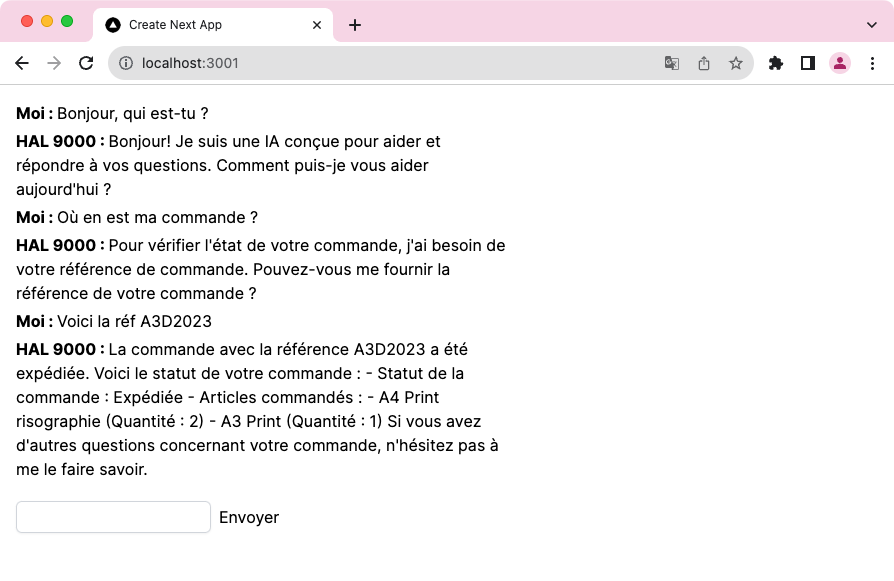
Et voici sa réponse si nous lui donnons une référence qui n'existe pas :
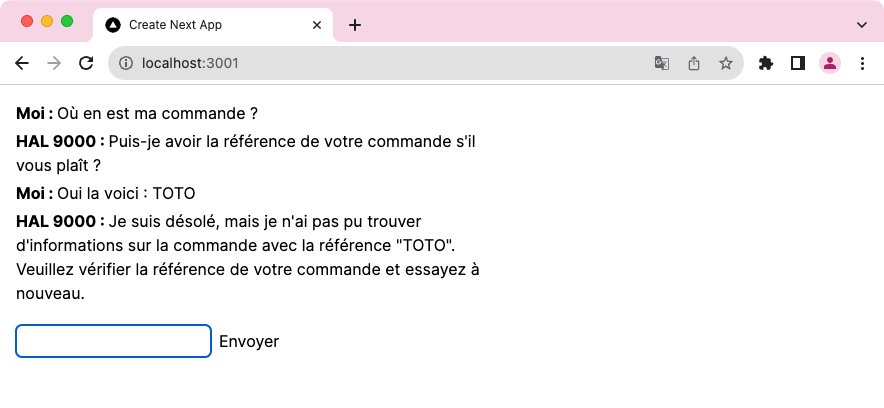
Nous n'avons pas de contrôle direct sur le moment où le modèle décide d'appeler notre fonction, cependant, nous pouvons lui fournir des indices en utilisant :
- la description de la fonction ;
- un prompt initial permettant de donner des instructions précises au modèle.
Pour conclure
Nous avons vu comment alimenter un modèle GPT avec nos propres données. Dans cet exemple, nous lui avons fourni qu’une seule fonction : nous pourrions couvrir des workflows plus complexes en lui donnant plus de fonctions. GPT est d’ailleurs capable d’imbriquer des appels de fonctions si besoin.
Notre rôle ici est donc de donner le plus de contexte possible au modèle afin qu’il puisse trouver les bonnes informations et l'appliquer à son système de raisonnement. Il est aussi important de lui fournir des gardes fous pour éviter qu'il ne s'égare vers des voies non souhaitées.
Le développement avec des LLMs introduit donc un léger changement de paradigme : l’algorithme pur et dur s’efface au profit d’un modèle de raisonnement auquel nous devons communiquer des informations pour qu'il s'appuie dessus.
Il convient cependant de relever quelques points de vigilances :
- vos données transitent par l’API d’OpenAI, ce qui peut poser des problèmes de confidentialité ;
- chaque appel à l’API d’OpenAI à un coût qui varie selon le modèle appelé.
Ces quelques points évacués, il n’en reste pas moins fascinant de travailler avec des LLMs !
Retrouvez le code du projet sur GitHub.
Références :